韩国科学技术院(KAIST)近期发表一篇长达 371 页的论文,详细描绘高频宽记忆体(HBM)技术至 2038 年的演进路线,涵盖频宽、容量、I/O 宽度与热功耗等面向的成长。该蓝图涵盖从 HBM4 到 HBM8 的技术发展,包括先进封装、3D 堆叠、嵌入式 NAND 储存的记忆体中心架构,以及以机器学习为基础的功耗控制手法。
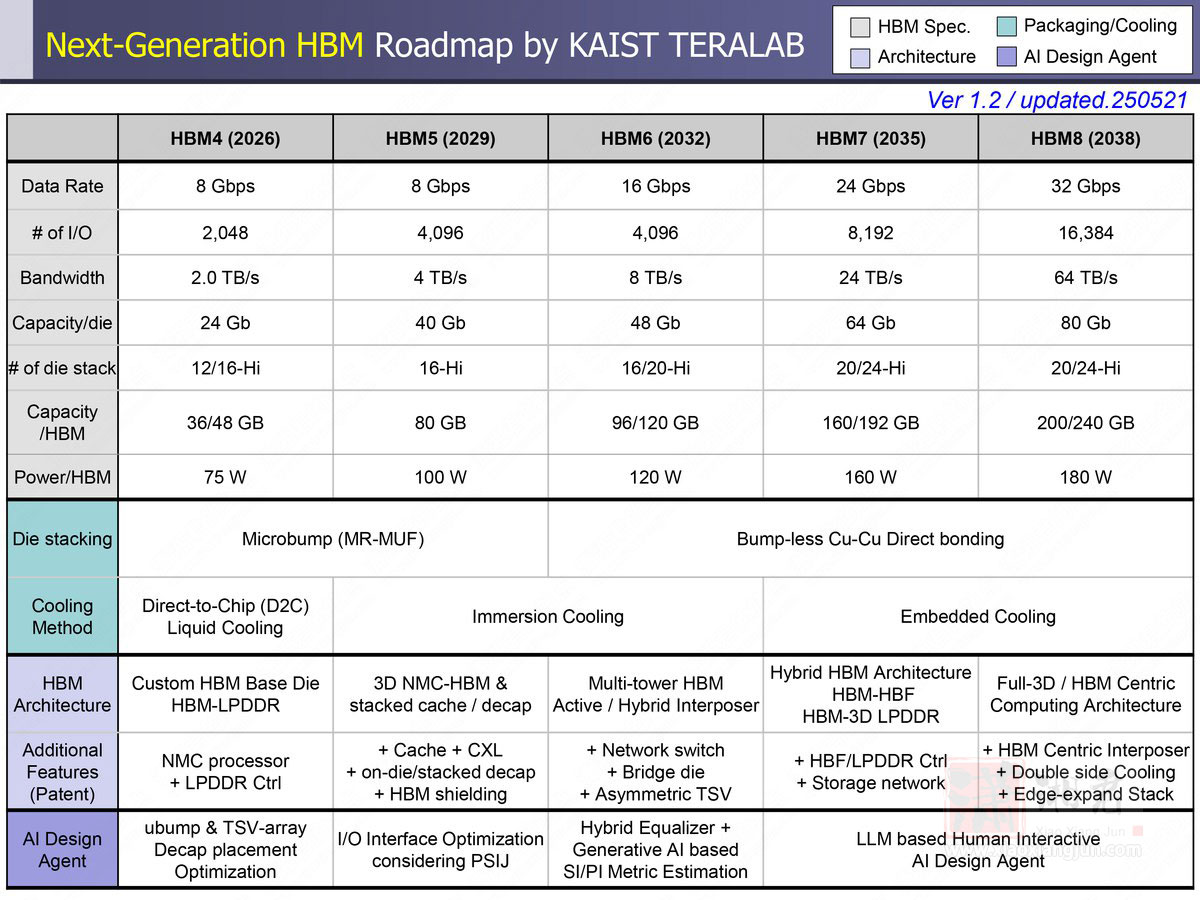
根据该蓝图,HBM 单堆叠容量将从 HBM4 的 288GB 增加至 384GB,HBM7 容量增加至 5,120GB 至 6,144GB;每个堆叠的功耗也提升,从 HBM4 的 75W 增至 HBM8 的 180W。

在 2026 年至 2038 年间,HBM 的频宽预期将从 2 TB/s 成长至 64 TB/s,数据传输速率则从 8 GT/s 提升至 32 GT/s;I/O 数从 HBM3E 的 1,024,增加到 HBM4 的 2,048,最终在 HBM8 高达 16,384。
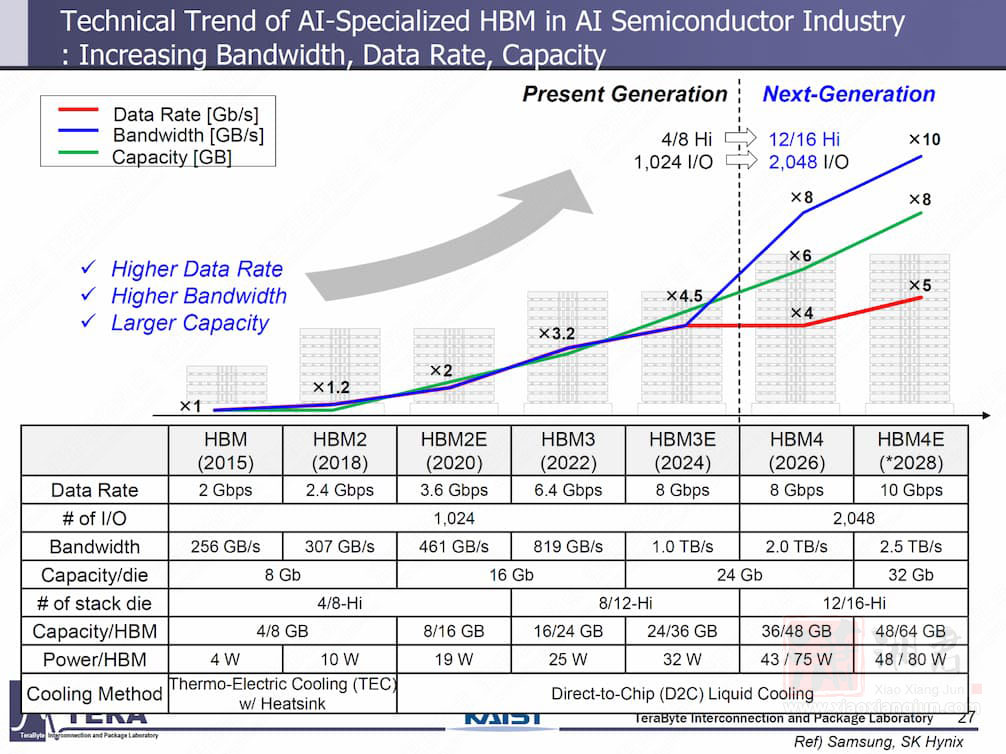
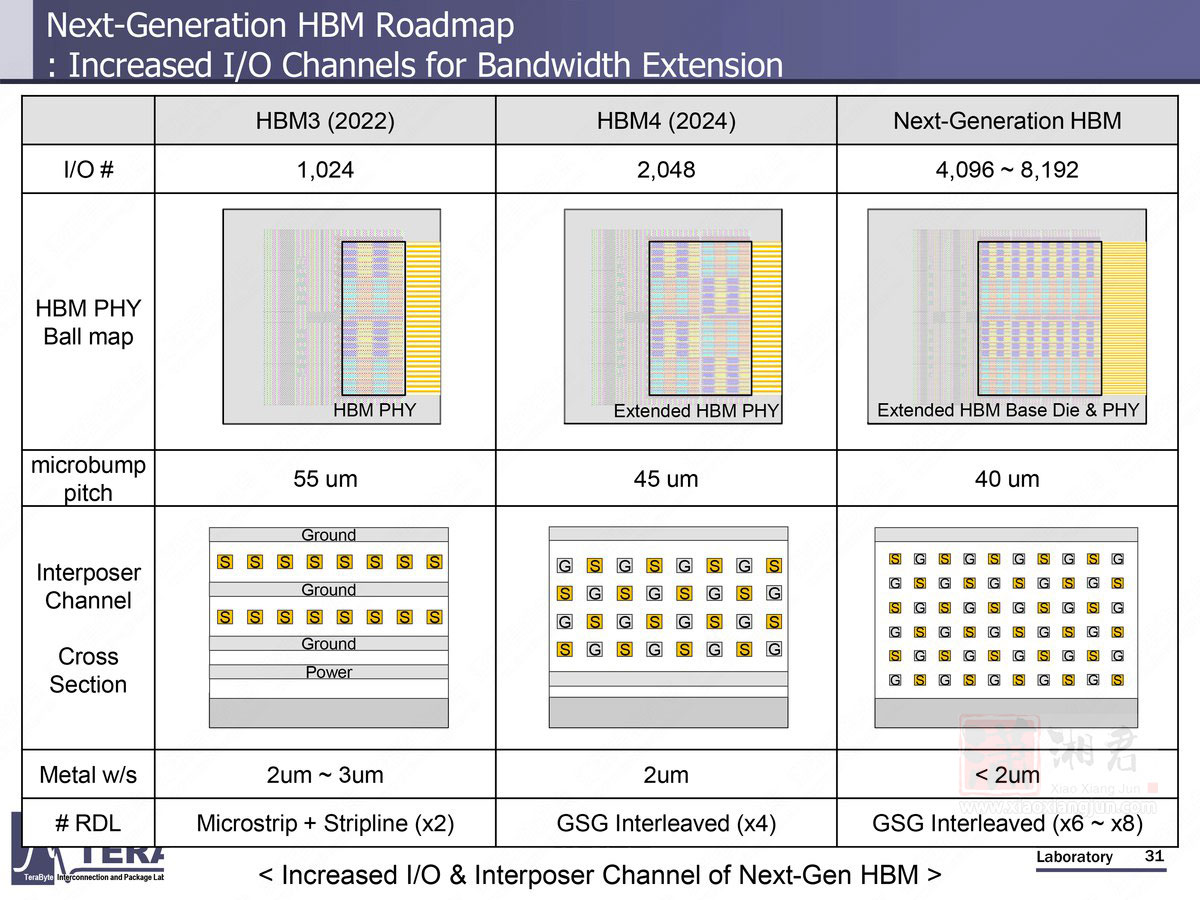
报导称,目前 HBM4 技术已大致明朗,而 HBM4E 则透过客制化的基础晶片(base die)设计,针对 AI、高效能运算(HPC)、网通等应用提供更大弹性。

预期 2029 年推出的 HBM5,将延续 HBM4 的数据传输速率,I/O 数则翻倍至 4,096、频宽升至 4 TB/s,单堆叠容量预期升至 80 GB、功耗达 100W,并需要更先进的散热技术。
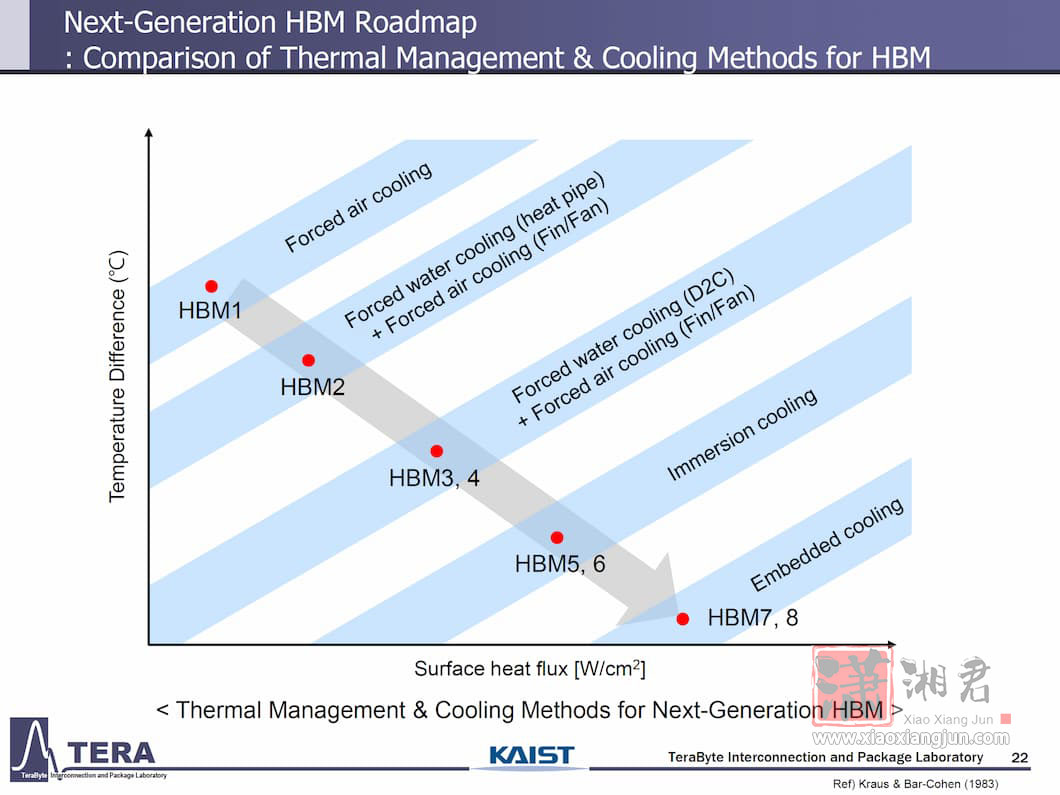
目前业界已在 HBM4 研究无焊接直接键合(direct bonding),KAIST 预期 HBM5 将继续采用 MR-MUF 技术。此外,HBM5 将整合 L3 快取、LPDDR、CXL 介面与热感应监控功能,并开始导入 AI 工具以最佳化实体布局。
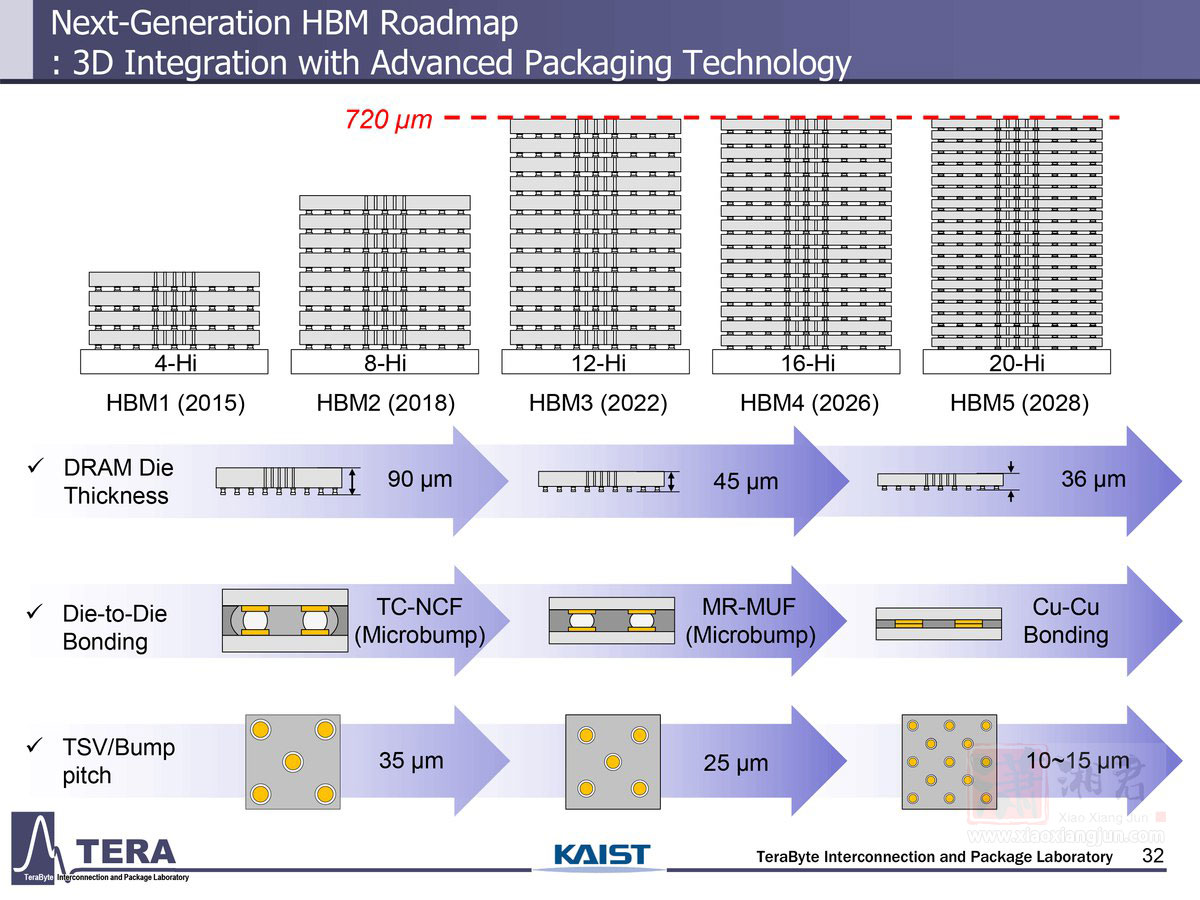

至于 HBM6 预期将于 2032 年接棒,传输速度将达 16 GT/s、频宽达 8 TB/s,单堆叠容量高达 120 GB、功耗为 120W。HBM6 将采用无凸块直接键合技术,并结合矽与玻璃的混合型中介层(hybrid interposer)设计。在架构部分,则导入多塔式(multi-tower)记忆体堆叠、内部网路交换机设计,以及大量矽穿孔(TSV)分布。AI 设计工具的应用范围也将扩大,导入生成式设计来进行讯号与电源建模。

到了 HBM7 和 HBM8,将进一步突破现有概念,两种都将採用无凸块直接键合技术,以及内嵌式冷却解决方案。其中,HBM7 也将引进全新的 HBM-HBF 和 HBM-3D LPDDR 架构。此外,採用 HBM7 的解决方案预期将走向超大型与多晶片组(multi-chiplet)设计。

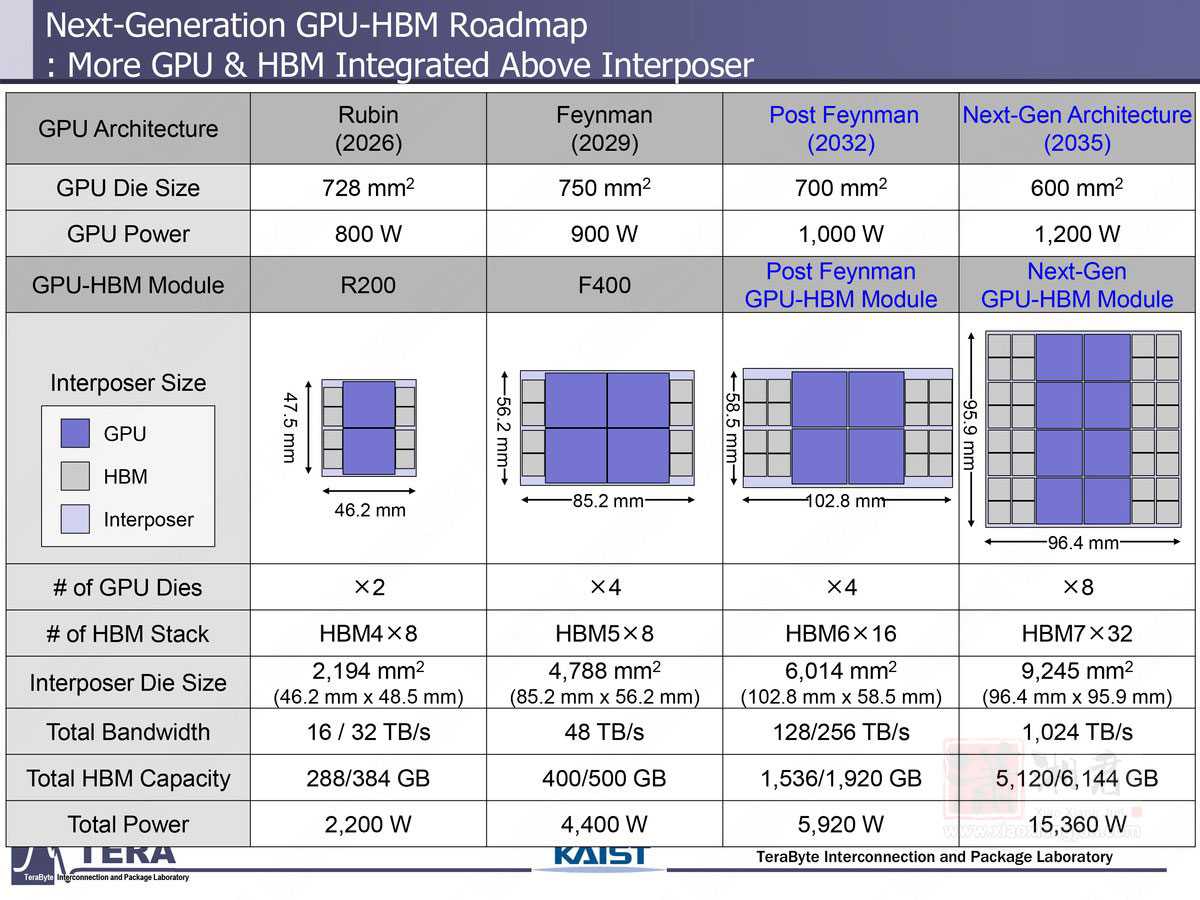
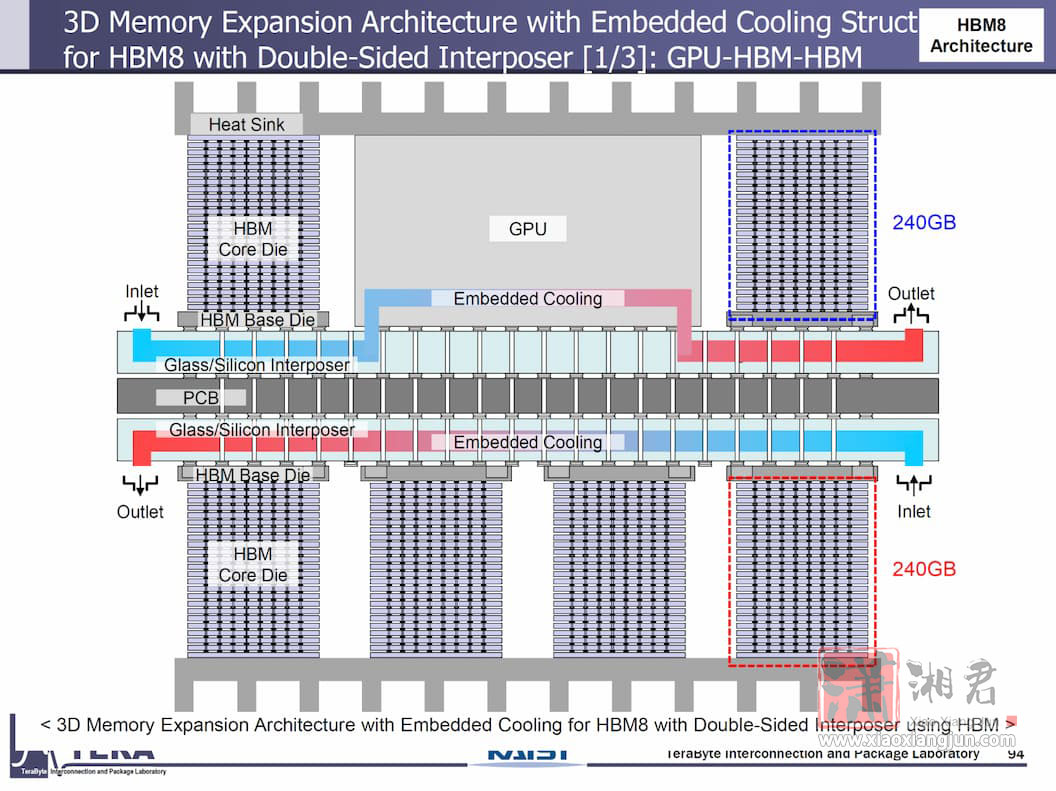
HBM8 传输速率将达 32 GT/s,单堆叠频宽高达 64 TB/s,容量预计可扩充至 240 GB。封装技术则进化为全 3D 堆叠并採用双面中介层(double-sided interposer)与内嵌式液冷通道。
其中,HBF(High-Bandwidth Flash) 架构主要为了解决记忆体密集型大型语言模型(LLM)推论所需的庞大容量需求。在 HBF 架构中,与传统使用 DRAM 不同,制造商会採用多达 128 层的 NAND 快闪记忆体,建构出 16 层堆叠,并透过专属的 HBF TSV 技术进行连接。
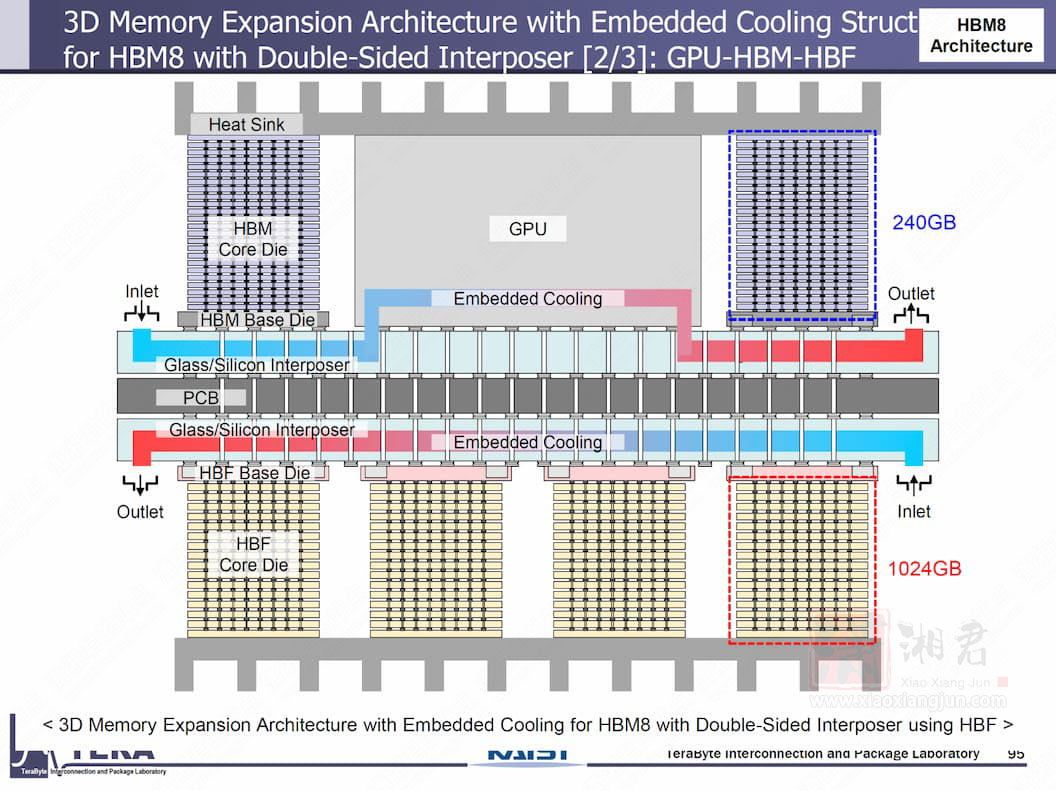
也因此,每一个 HBF 堆叠会与一个 HBM 堆叠并联,可额外提供高达 1TB 容量,并透过 2 TB/s 的 HBM 与 HBF 之间的高速互连进行资料交换。这些模组再透过主机板上的记忆体网路交换器(memory network switch),以 128 GB/s 的双向互连速率连接至其他元件。
虽然 HBM7 与 HBM8 名义上仍属于 HBM 家族,但架构预期将与现今所知的 HBM 不同。据悉,HBM5 引入 L3 快取与 LPDDR 介面,而 HBM7/8 则预期将导入 NAND 介面,使资料直接从储存装置移动至 HBM,仅需最少的CPU、GPU 或 ASIC 介入。
如此一来,每个堆叠功耗达 180W,而 KAIST 预期 AI 代理系统将管理散热、电源与讯号路径的最佳解。除了刚刚上述的 GPU、HBM、HBF 堆叠外,KAIST 也展示 GPU、HBM、HBM 堆叠,及 GPU、HBM、LPDDR 堆叠的示意图。
Tips
文章来源于 technews.tw,详情:click here.


文章评论