
一段时间以来, 我们一直想评测铠侠FL6,但直到偶然的 eBay 购买后,我们才得到了。进入我们的铠侠 FL6 评测。自从英特尔宣布其傲腾结束以来已经有一段时间了 。市场上没有这种新的存储级内存 SSD,现在高端 SSD 空间存在一个漏洞,用于可以处理一致的大量写入的驱动器。铠侠 FL6 旨在处理每天 60 次驱动器写入 (DWPD) 的耐用性,并提供一致的性能。
描述铠侠Kioxia FL6 800GB
铠侠 FL6 到货,看起来并不是特别令人兴奋。该驱动器的容量为 800GB,实际上是 PCIe Gen4 NVMe SSD 系列中较小的一端。驱动器范围高达 3.2TB。铠侠的方法与市场上其他提供 400GB 和 800GB 容量的同类驱动器不同。

驱动器本身是标准的 2.5 英寸 SSD 设计。

在这里,我们有自己的电源和数据连接。

我们还在驱动器的正面看到了一个诊断端口。铠侠驱动器也往往有穿孔,以允许一些气流通过驱动器本身。

到 2024 年,现代 SSD 的 800GB 并不是一个巨大的容量,因为这不是为了容量。相反,这适用于需要一致低延迟性能的重写入压力应用程序,例如日志记录、某些数据库功能等。随着数据中心 SSD 供应商瞄准硬盘驱动器市场,该行业的大部分已经过渡到更大的 TLC 和 QLC SSD。这被设计为主要以写入为中心的驱动器。

虽然我们最近很少谈论 NAND,但它在这里值得注意。虽然大部分容量市场已经转向 160 层到 200+ 层 NAND,但这仍然是在 96 层 NAND 上。该驱动器的基础是铠侠 XL-Flash 存储器。
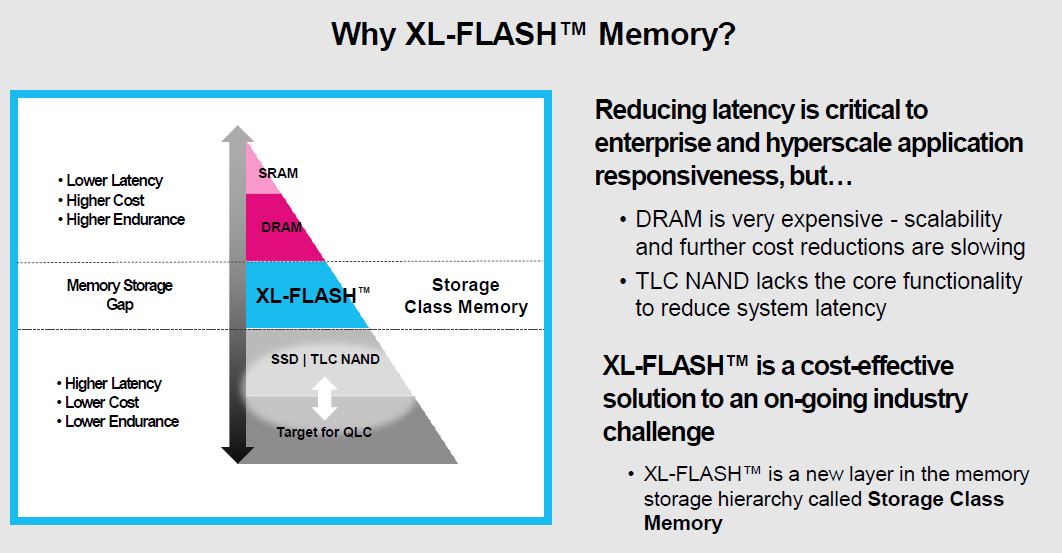
据我们了解,这是在 SLC 模式下运行的第一代 XL-FLASH,但第二代 XL-FLASH 设置为基于 MLC。
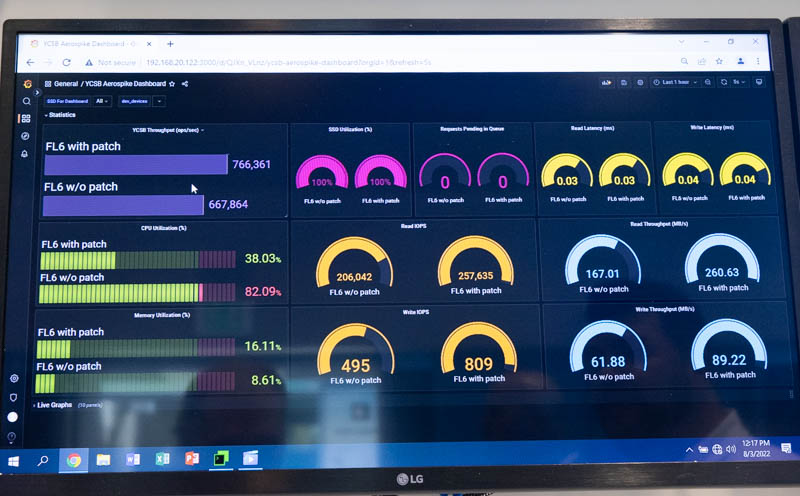
虽然我们从未使用过该驱动器,但我们看到它运行演示,例如使用 FL6 作为存储类内存运行 YCSB 的修补 Aerospike 数据库。
现在,我们有机会在动手审查中了解一个,让我们接下来开始。
铠侠FL6 800GB 基本性能
为此,我们将运行许多工作负载,只是为了了解铠侠 FL6 的性能。我们还想提供一些桌面工具的简单屏幕截图,以便您可以快速轻松地与您可能拥有的其他驱动器进行比较。
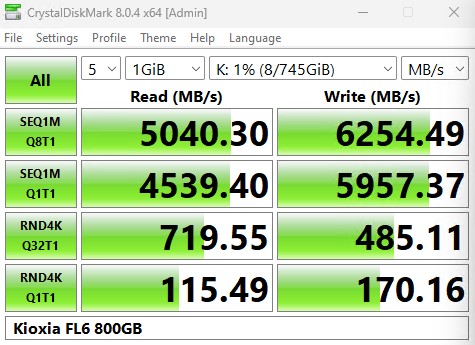
CrystalDiskMark 被用作基准测试的基本起点,因为它通常是最终用户作为健全性检查运行的东西。以下是较小的 1GB 测试大小:
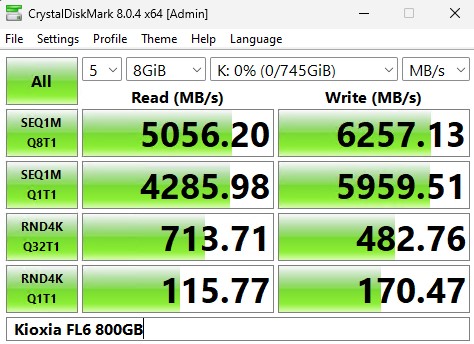
以下是较大的 8GB 测试大小:
如果您想并排查看,它们在这里:
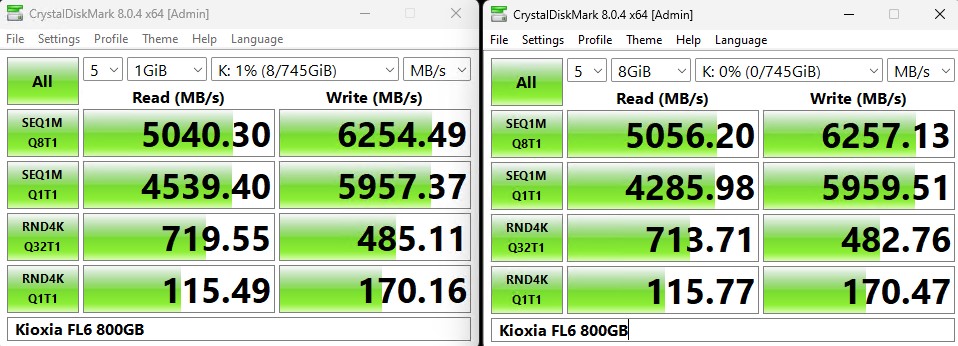
尽管 4K 随机读取 Q32T1 数字高于该队列深度的写入数据,但其余指标偏向写入列。这正是以写入为中心的驱动器的重点,但也与我们从大多数专为读取工作负载设计的驱动器中看到的完全相反。
ATTO 磁盘基准测试
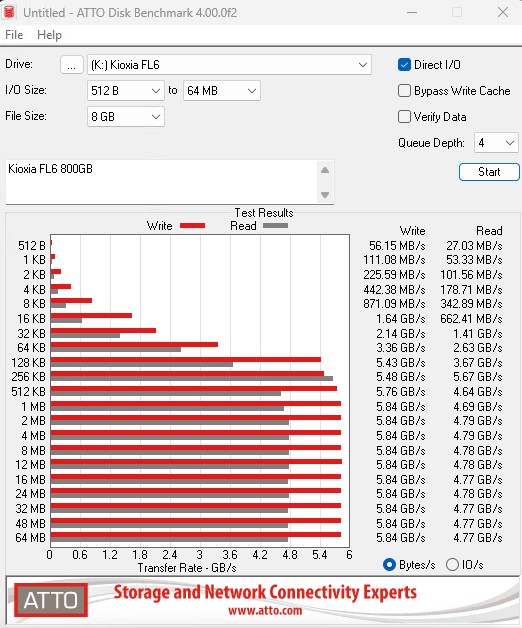
多年来,ATTO Disk Benchmark 一直是硬盘顺序性能测试的主要内容。ATTO 在 256MB 和 8GB 文件大小下进行了测试。
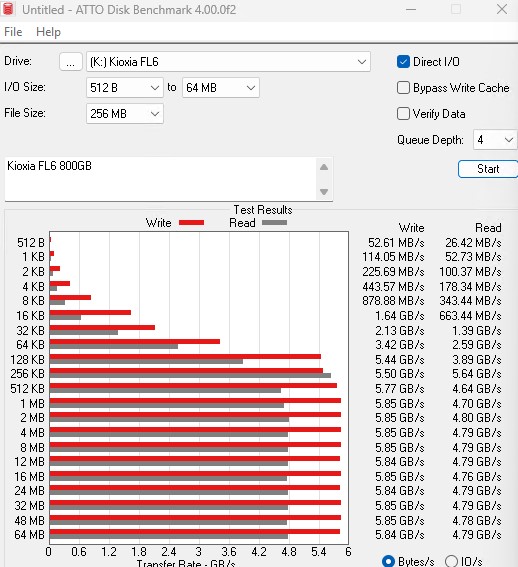
这是 8GB 的结果:
对于那些想要并排查看结果比较的人:
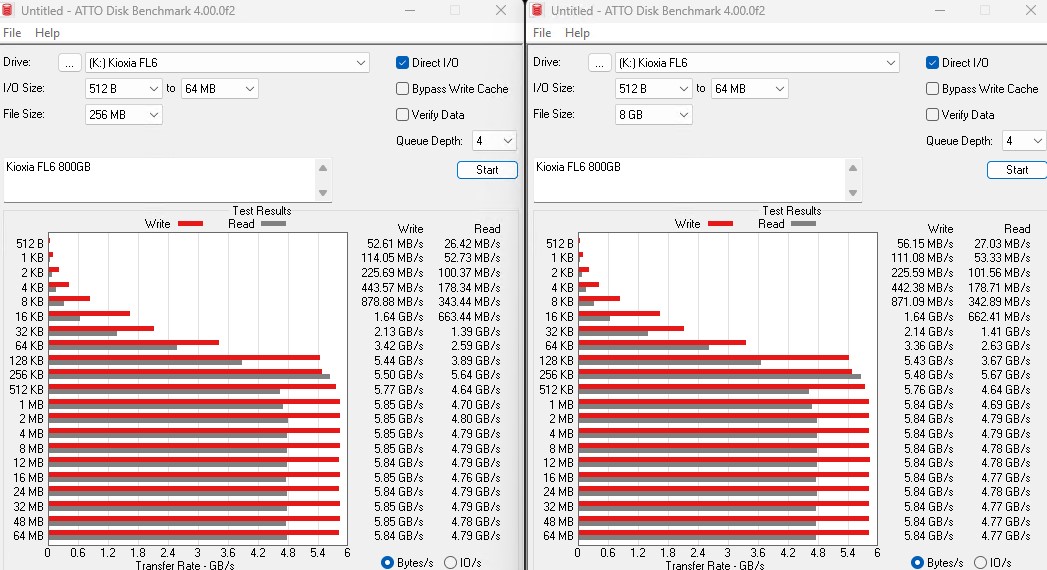
同样,与读取相比,该驱动器在写入列中的性能非常好,除了 256KB。这个 256KB 感觉像是驱动器配置的怪癖或特定的优化,因为它与其他数字不一致。我们购买了不止一个驱动器,它们都表现出这种行为。
AS SSD 基准测试
AS SSD Benchmark 是测试 SSD 的另一个很好的基准。我们为我们的系列运行了所有三个测试。与其他实用程序一样,它使用默认的 1GB 和更大的 10GB 测试集运行。
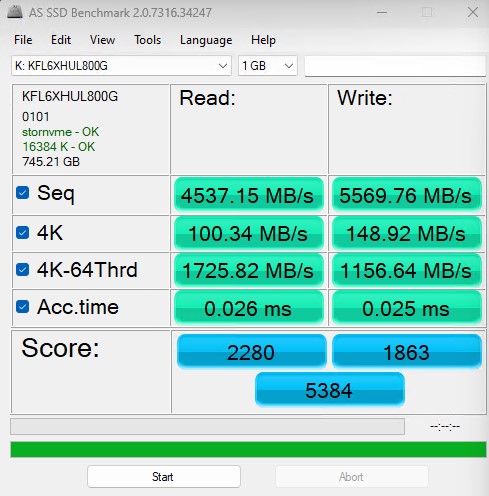
以下是 10GB 测试大小:
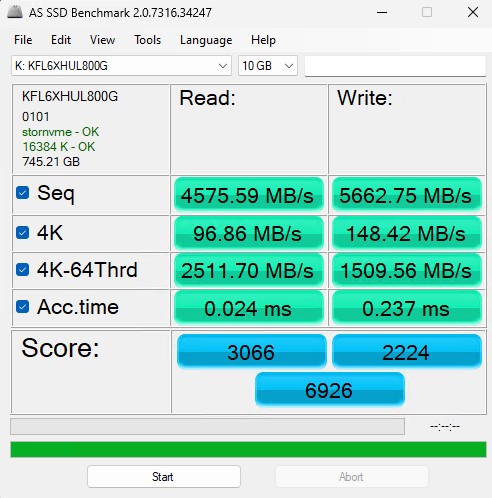
同样,并排显示两者测试图片。
同样,在较高的队列深度随机 4K 工作负载中,读取分数更高,但除此之外,写入分数更高。
接下来,让我们来了解一些基于 Linux 的基准测试。
铠侠 FL6 Four Corners Performance
我们的第一个测试是查看铠侠 FL6 的顺序传输速率和 4K 随机 IOPS 性能。请原谅小于正常情况的比较集。在下一节中,您将了解为什么我们的比较集减少了。主要原因是我们切换到了一个多架构测试实验室。我们在 PCIe Gen4 和 Gen5 的 20 多种不同的处理器架构中测试了这些。尽管如此,我们还是想看看驱动器的性能。
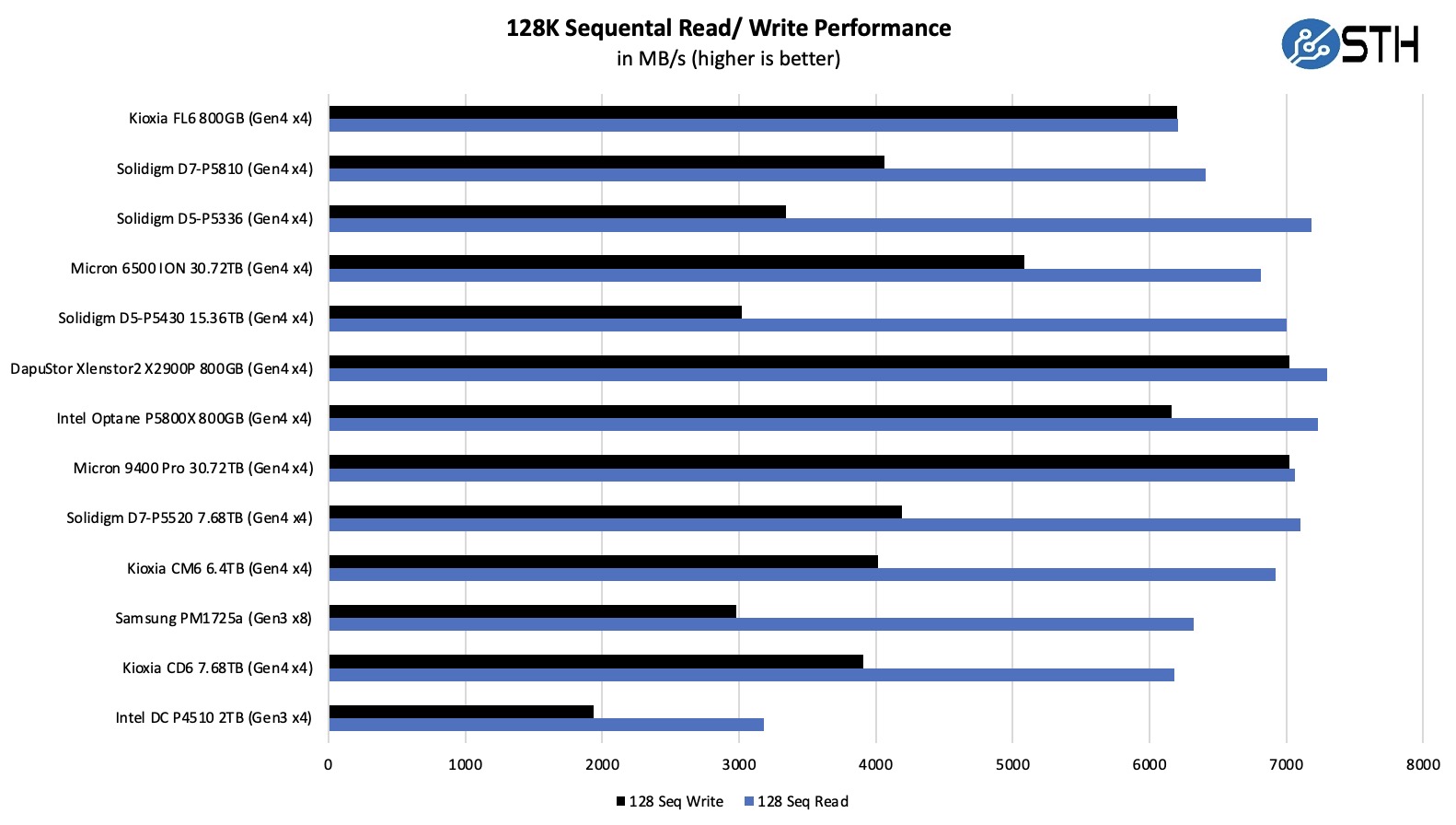
以下是 4K 随机读写性能:
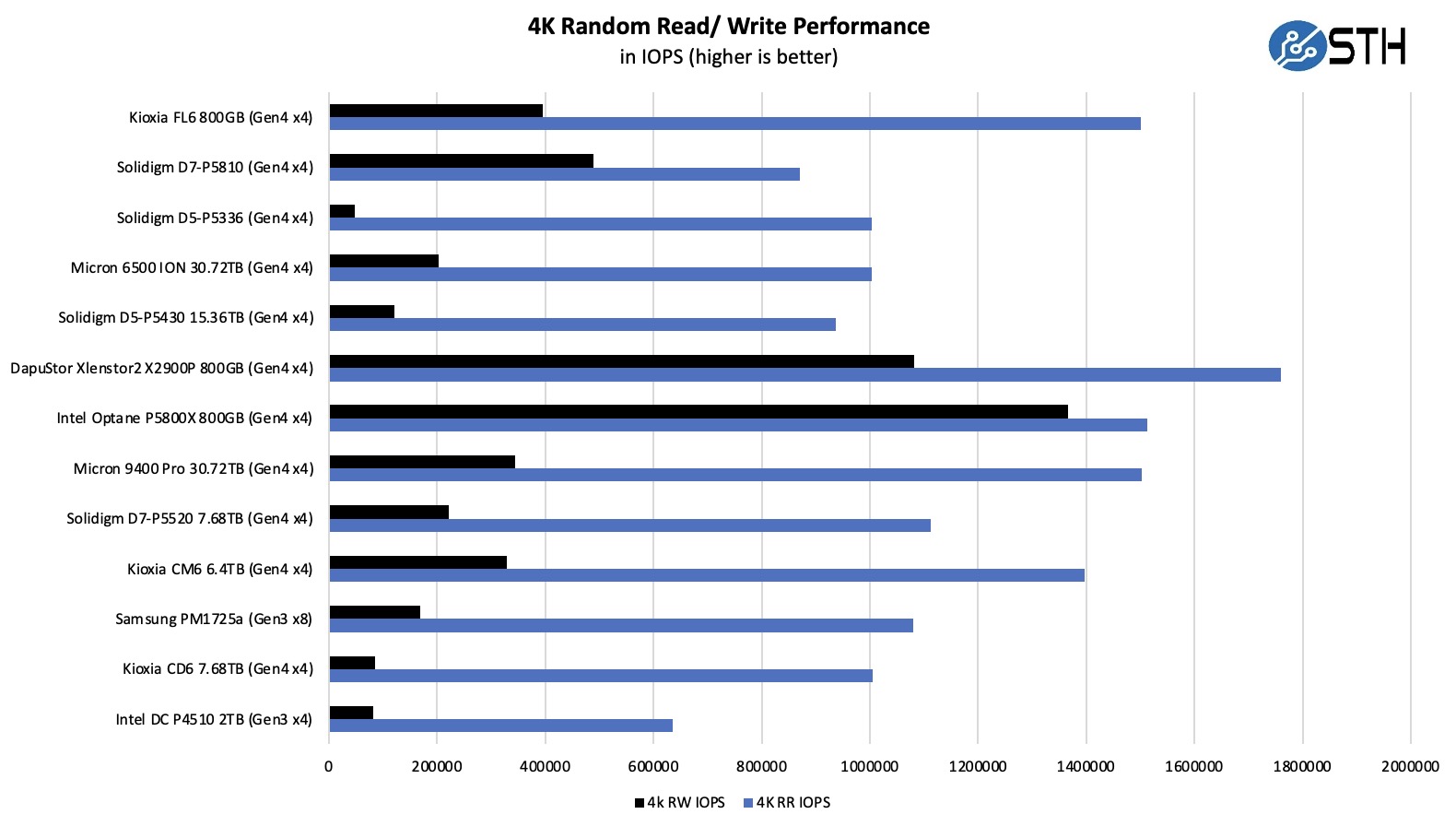
在较长的测试运行中,4K 随机读取数据确实有所提高。铠侠的解决方案可以明显超过 Solidigm 的解决方案。与此同时,同样使用铠侠 XL-FLASH 的 DapuStor Xlenstor2 X2900P 是一头野兽。
铠侠 FL6 应用程序性能比较
对于我们的应用程序测试性能,我们仍在使用 AMD EPYC。我们让所有这些工作都在 x86 上,但我们还没有在 Arm 和 POWER9 上工作,所以这仍然是一个 x86 工作负载。
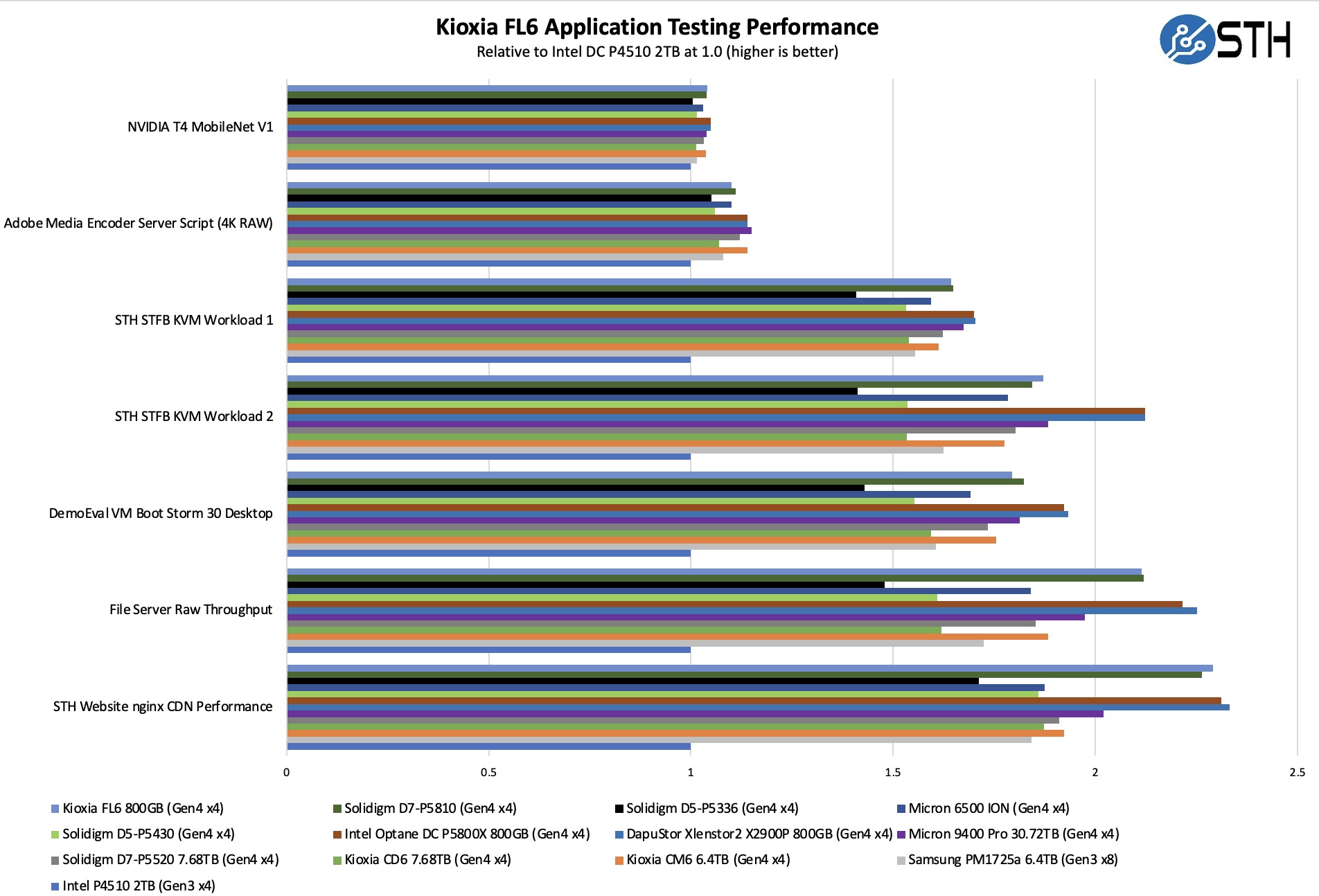
如您所见,就铠侠 FL6 对应用程序性能的影响程度而言,这里存在很多变化。让我们来讨论一下性能驱动因素。
在 NVIDIA T4 MobileNet V1 脚本上,我们看到对 AI 工作负载的性能影响很小,但我们看到了一些。这里的关键是 NVIDIA T4 的性能主要限制了我们,存储不是瓶颈。我们有一个 NVIDIA L4,将来将与更新的模型一起使用。在这里,我们可以看到较新驱动器在性能方面的好处,但并不是很大。这是整体故事的一部分。大多数存储产品的评论主要集中在线路上,看到 PCIe Gen3 到 PCIe Gen4 的顺序吞吐量翻倍可能令人兴奋,但在许多实际工作负载中,系统的压力不仅仅在于存储。
同样,我们的 Adobe Media Encoder 脚本会定时复制到驱动器,然后转码视频文件,然后传输驱动器。在这里,我们的影响更大,因为我们涉及一些较大的顺序读/写,主要性能驱动因素是编码速度。这些测试的关键要点是,如果您主要受计算限制,但仍需要为工作流程的某些部分转到存储,那么 SSD 可以在端到端工作流程中发挥作用。
在 KVM 虚拟化测试中,我们看到对存储的依赖程度更高。 第一个 KVM 虚拟化( 工作负载 1 )比 工作负载 2 或 VM Boot Storm 工作负载受 CPU 限制更多,因此我们看到了强大的性能,尽管不如其他两个虚拟化。 这些是基于 KVM 虚拟化的工作负载,我们的客户正在测试在给定时间可以在线多少个虚拟机,同时在目标 SLA 下完成工作。每个 VM 都是一个独立的工作线程。根据我们的性能分析,我们知道,由于使用了数据库,工作负载 2 实际上可以通过快速存储和傲腾 PMem 更好地扩展。同时,如果数据集更大,PMem 就没有扩展能力,它正在作为一项技术停止使用。这种分析也是我们在 CPU 评估中使用工作负载 1 的原因。铠侠的随机 IOPS 性能在这里确实有帮助。在工作负载 2 和 VM Boot Storm 上,我们看到驱动器的性能非常好。
转到文件服务器 和 nginx CDN, 我们看到铠侠 SSD 提供了许多稳定的 QoS 和吞吐量。由于其更快的顺序速度,该驱动器在文件服务器上领先。在 nginx CDN 测试中,我们使用来自 STH 网站的旧快照和访问模式,禁用缓存,以显示在这种情况下的性能。以下是分布的快速浏览:
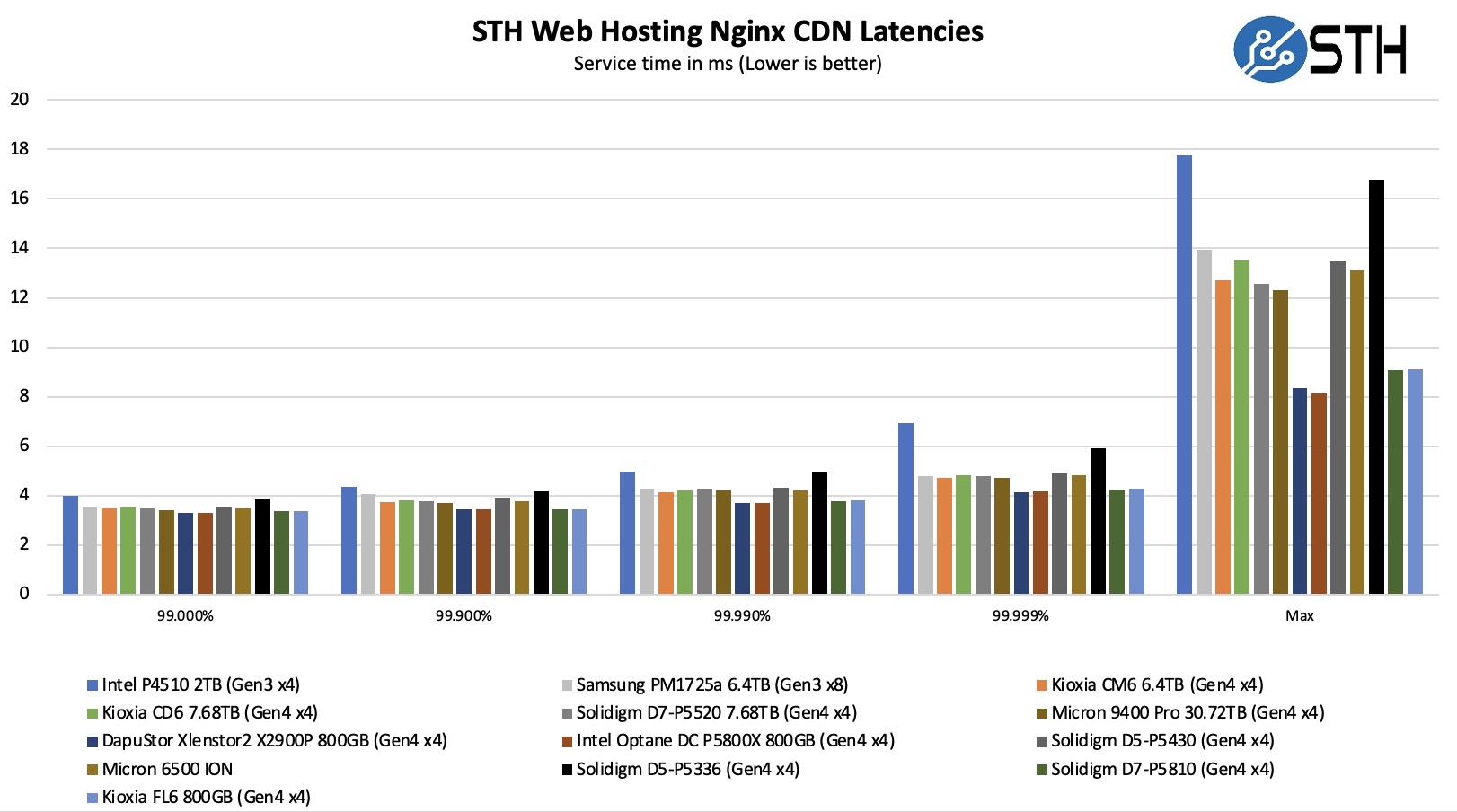
在这里,我们可以真正看到 SCM 级设备和以容量为中心的 SSD 之间的巨大差异。在 99% 的间隔处,差距并不过分。当我们达到 5-9 时,差距是巨大的。铠侠FL6 属于本次测试中性能更好的驱动器类别。
现在,对于大项目:我们使用所有 PCIe Gen4 架构和我们能找到的所有新 PCIe Gen5 架构测试了这些驱动器,而不仅仅是 x86,甚至不仅仅是美国可用的服务器。
铠侠FL6 800GB CPU 架构的性能
如果您看过我们最近的 2022-2023 年更多内核、更好的 AMD Arm 和 Intel 服务器 CPU 的文章,或者我们的文章, 如 Supermicro ARS-210ME-FNR Ampere Altra Max Arm 服务器评测 、 华为海思鲲鹏 920 Arm 服务器 文章,您可能已经看到我们一直在扩展我们的测试平台以包括更多架构。这是对 Oracle Cloud、 Microsoft Azure 和 Google Cloud 使用的 系列的 Ampere Altra 80 核 CPU 的补充。我们还设法在最新一代 AMD EPYC Bergamo 和 Genoa-X SKU 上测试了这些。
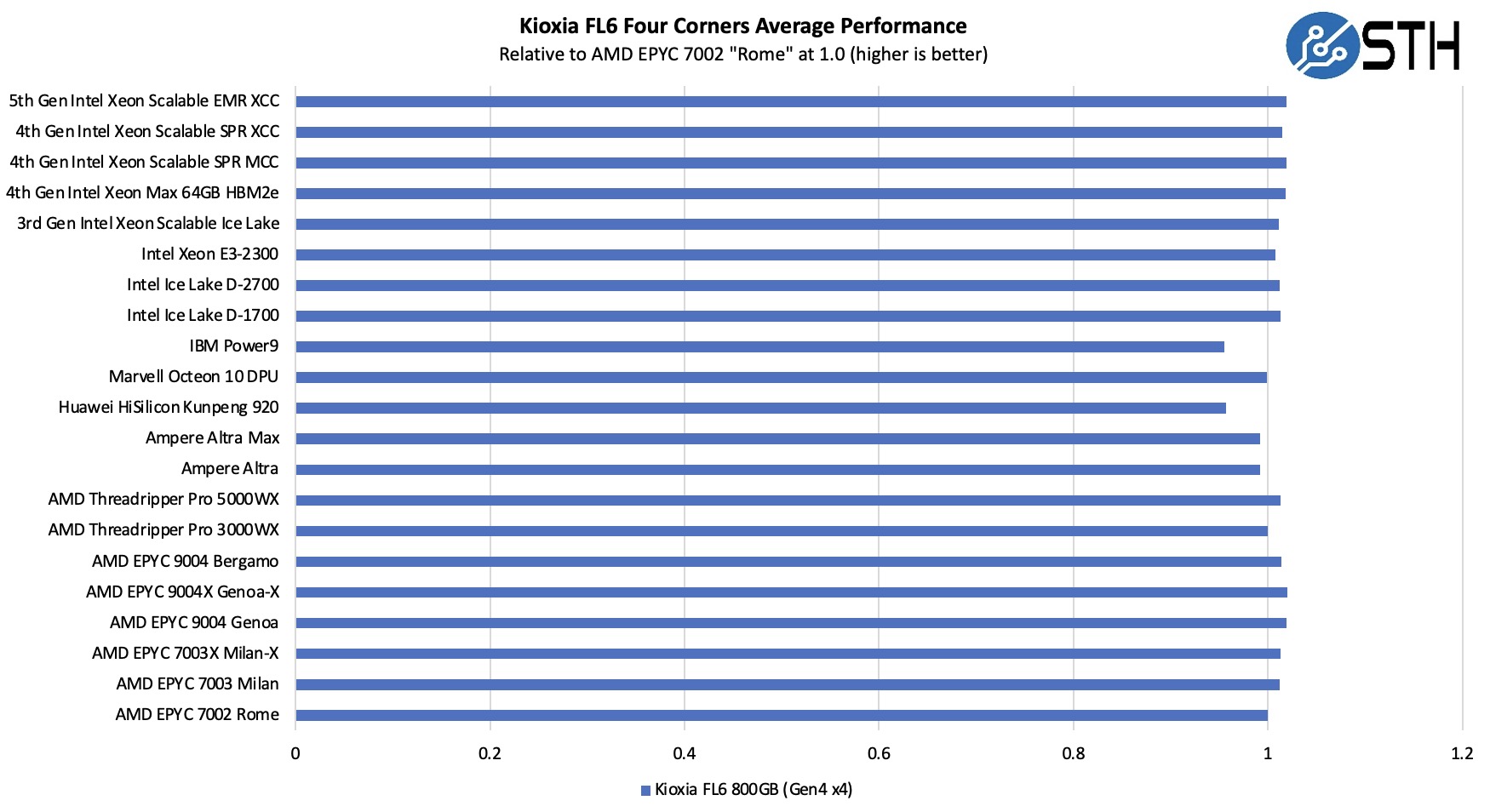
由于这很难阅读,我们在下面有一个没有 0 X 轴的放大视图。
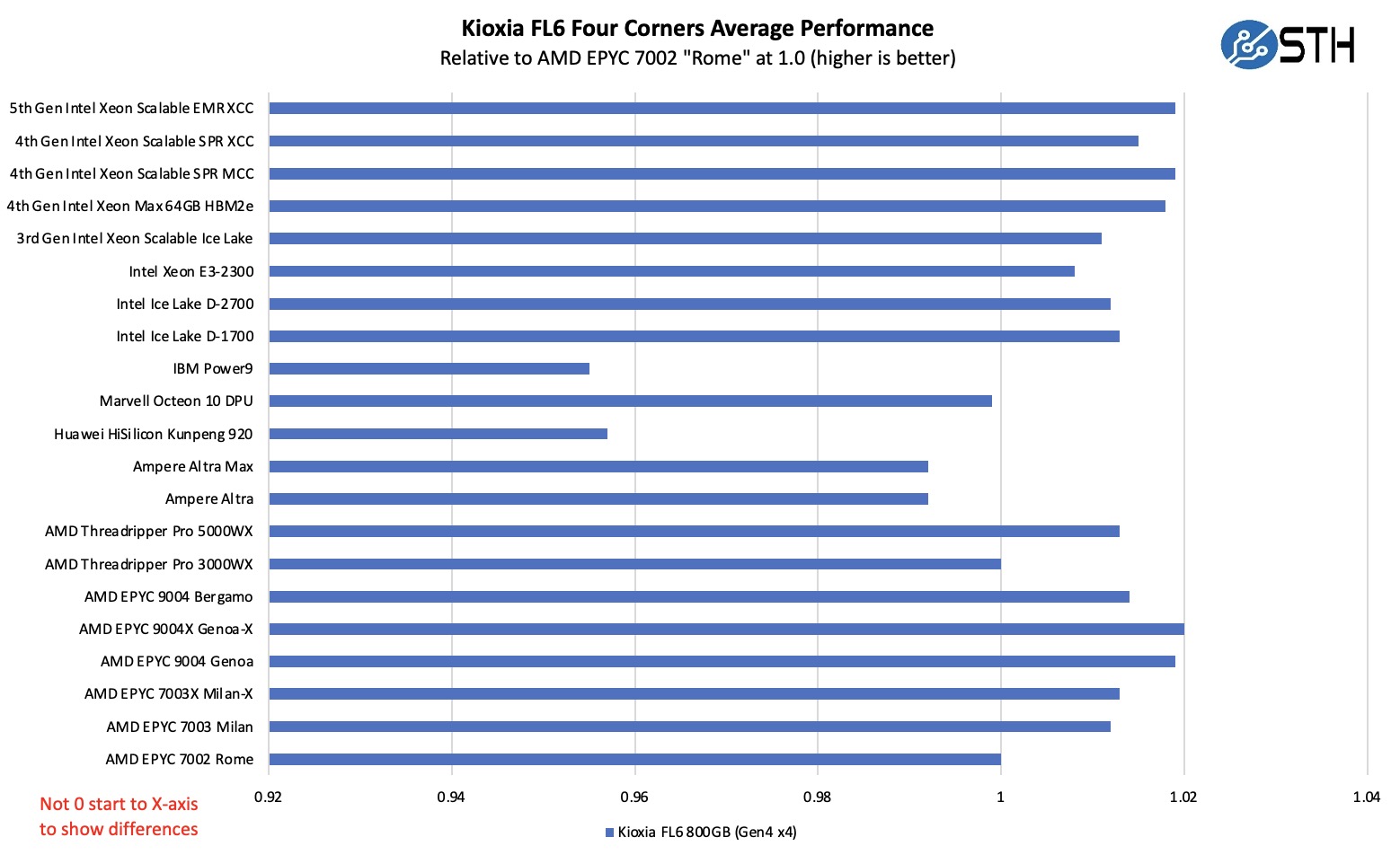
一般来说,这个驱动器在较新的 PCIe Gen4 和 Gen5 x86 控制器上表现良好。Arm 和 IBM Power9 控制器通常较慢,这正是我们在这里看到的。在这一点上没有什么惊喜。

在这个版本中,我们最高拥有代号为“Emerald Rapids”的第 5 代 Intel Xeon。仅根据测试窗口,我们没有在 Intel Xeon 6 Sierra Forest 系统中测试这些。但是,我们确实将它们放入了更新的 AMD EPYC 平台。
有趣的是,并非所有 PCIe 控制器都是一样创建的。

最后
铠侠FL6 并不是该公司最新的驱动器。这款 SSD 于 2021 年发布 ,我们在 2022 年第三季度首次看到它。尽管如此,整体驱动器类别往往随着时间的推移而缓慢移动,发布频率远低于我们在以读取为中心的容量部分看到的。我们设法在这些方面获得了很多东西,所以我们认为我们至少会分享我们从他们那里看到的东西。
60 DWPD 很多。在下周的 FMS 2024 上,我们将讨论 60 DWPD 是否是现代 SSD(尤其是容量 SSD)的正确指标。我们还将对我们于 2013 年在 SSD 领域开始的一个有趣项目进行更新。尽管如此,仍有一些日志记录设备、缓存设备等真正专注于繁重的写入工作负载。如果您确实有大量写入工作负载,那么铠侠 FL6 旨在通过持续将数据写入 NAND 来满足这些需求。
Tips
文章来源于STH,详情请查询:click here.


文章评论